Mybatis简介
JDBC定义了连接数据库的接口规范,每个数据库厂商都会提供具体的实现,JDBC是一种典型的桥接模式。
传统的JDBC编程
- 获取数据库连接;
- 操作Connection,打开Statement对象;
- 通过Statement对象执行SQL,返回结果到ResultSet对象;
- 关闭数据库资源
1 | public class javaTest { |
Hibernate与Mybatis
Hibernate建立在POJO和数据库表模型的直接映射关系上。通过POJO我们可以直接操作数据库的数据。相对而言,Hibernate对JDBC的封装程度比较高,我们不需要编写SQL,直接通过HQL去操作POJO进而操作数据库的数据。
Mybatis是半自动映射的orm框架,它需要我们提供POJO,SQL和映射关系,而全表映射的Hibernate只需要提供POJO和映射关系。
Hibernate编程简单,需要我们提供映射的规则,完全可以通过IDE实现,同时无需编写SQL,开发效率优于Mybatis。此外,它提供缓存、级联、日志等强大的功能,
Hibernate与Mybatis区别:
Hibernate是全自动,而Mybatis是半自动。
Hibernate是全表映射,可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而Mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。Hibernate数据库移植性较好。
Hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库的耦合性,而Mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。Hibernate拥有完整的日志系统,Mybatis则欠缺一些。
Hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而Mybatis则除了基本记录功能外,功能薄弱很多。sql直接优化上,Mybatis要比Hibernate方便很多。
由于Mybatis的sql都是写在xml里,因此优化sql比Hibernate方便很多,解除了sql与代码的耦合。而Hibernate的sql很多都是自动生成的,无法直接维护sql;写sql的灵活度上Hibernate不及Mybatis。Mybatis提供xml标签,支持编写动态sql。
Mybatis入门
SqlSessionFactory
使用xml构建SqlSessionFactory,配置信息在mybatis-config.xml
1 |
|
1 | import org.apache.ibatis.io.Resources; |
SqlSession
SqlSession是接口类,扮演门面的作用,真正处理数据的是Executor接口。在Mybatis中SqlSession的实现类有DefaultSqlSession和SqlSessionManager。
映射器Mapper
映射器的实现方式有两种:通过xml方式实现,在mybatis-config.xml中定义Mapper;通过代码方式实现,在Configuration里面注册Mapper接口。建议使用xml配置方式,这种方式比较灵活,尤其当SQL语句很复杂时。
xml文件配置方式实现Mapper
1 | public interface RoleMapper { |
映射xml文件RoleMapper.xml
1 |
|
测试类
1 | import com.tyson.mapper.RoleMapper; |
Java方式实现Mapper
1 | import com.tyson.pojo.Role; |
在Mybatis全局配置文件注册Mapper,有三种方式。
1 | <!--定义映射器--> |
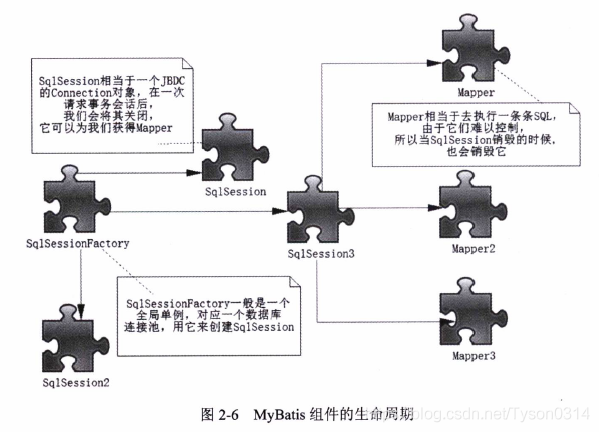
Mybatis组件的生命周期
- SqlSessionFactoryBuilder
作用是生成SqlSessionFactory,构建完毕则作用完结,生命周期只存在于方法的局部。
- SqlSessionFactory
创建SqlSession,每次访问数据库都需要通过SqlSessionFactory创建SqlSession。故SqlSessionFactory应存在于Mybatis应用的整个生命周期。
- SqlSession
会话,相当于JDBC的Connection对象,生命周期为请求数据库处理事务的过程。
- Mapper
作用是发送SQL,返回结果或执行SLQ修改数据库数据,它的生命周期在一个SqlSession事务方法之内。其最大的作用范围和SqlSession相同。
配置
Mybatis全局配置文件mybatis-config.xml的层次结构顺序不能颠倒,否则在解析xml文件会产生异常。
1 | <?xml version="1.0" encoding="UTF-8"?> |
properties
1 | <properties resource="db.properties"/> |
1 | driver=com.mysql.jdbc.Driver |
typeAliases
1 | <!--定义别名--> |
typeHandler
参考自:关于mybatis中typeHandler的两个案例
类型处理器,作用是将参数从javaType转化为jdbcType,或者从数据库取出结果时把jdbcType转化成javaType。typeHandler和别名一样,分为系统定义和用户自定义。Mybatis系统定义的typeHandler就可以实现大部分的功能。
1 | public TypeHandlerRegistry() { |
自定义typeHandler
假如需要将日期以字符串格式(转化成毫秒数)写进数据库,此时可以通过自定义typeHandler来实现此功能。
role表
1 | CREATE TABLE `role` ( |
Role实体类
1 | import java.util.Date; |
- 首先定义TypeHandler实现类(或继承BaseTypeHandler,BaseTypeHandler是TypeHandler的实现类)。在setNonNullParameter方法中,我们重新定义要写往数据库的数据。 在另外三个方法中我们将从数据库读出的数据进行类型转换。
1 | import lombok.extern.slf4j.Slf4j; |
- 在mybatis-config.xml中国注册自定义的typeHandler。单独配置或者扫描包的形式。注册之后数据的读写会被这个类过滤。
1 | <!--类型处理器--> |
- 在RoleMapper.xml编写SQL语句,resultMap中的转换字段需要指定相应的jdbcType和javaType,启动我们自定义的typeHandler,本例中应设置reg_time字段jdbcType为VARCHAR,对应的regTime属性javaType设置为java.util.Date,与MyDateTypeHandler处理类型匹配,所以对reg_time字段的读取会先经过MyDateTypeHandler的处理。插入的时候不会启用我们自定义的typeHandler,需要在insert标签配置typeHandler(或指定jdbcType和javaType)。
1 |
|
枚举类型typeHandler
Mybatis内部提供了两个转化枚举类型的typeHandler:org.apache.ibatis.type.EnumTypeHandler和org.apache.apache.ibatis.type.EnumOrdinalTypeHandler。EnumTypeHandler使用枚举字符串名称作为参数传递,EnumOrdinalTypeHandler使用整数下标作为参数传递。
下面通过EnumOrdinalTypeHandler实现性别枚举。
1 | public enum Sex { |
StudentMapper.java
1 | public interface StudentMapper { |
StudentMapper.xml
1 |
|
测试类
1 | import com.tyson.entity.Sex; |
插入的sex字段为INTEGER,测试结果如下:

通过EnumTypeHandler实现性别枚举只需修改StudentMapper.xml相应的typeHandler,修改如下:
1 |
|
插入的sex字段为VARCHAR类型,测试结果如下:

自定义枚举类typeHandler
SexEnumTypeHandler类的定义。
1 | import com.tyson.entity.Sex; |
mybatis-config.xml增加SexEnumTypeHandler的定义
1 | <typeHandlers> |
StudentMapper.xml
1 |
|
测试结果如下:
objectFactory
当Mybatis在构建一个结果返回时,都会使用ObjectFactory去构建POJO,可以定制自己的对象工厂。一般使用默认的ObjectFactory即可,默认的ObjectFactory为org.apache.ibatis.reflection.factory.DefaultObjectFactory提。
environments
配置环境可以注册多个数据源,每一个数据源分为两部分的配置:数据库源的配置和数据库事务的配置。
1 | <!--默认使用development数据库构建环境--> |
- environments的default属性,表明在缺省的情况下,将使用哪个数据源配置。
- transactionManager配置的是数据库事务,其type属性有三种配置方式。
(1)JDBC,使用JDBC管理事务,独立编码时常常使用;
(2)MANAGED,使用容器方式管理事务,在JNDI数据源中常用;
(3)自定义,由使用者自定义数据库管理方式,适用于特殊应用。
- dataSource标签,配置数据源连接的信息,type属性提供数据库连接方式的配置:
(1)UNPOOLED,非连接池数据库
(2)POOLED,连接池数据库
(3)JNDI数据源
(4)自定义数据源
数据库事务
Mybatis数据库事务由SqlSession控制,我们可以通过SqlSession提交或回滚。
1 |
|
映射器
select元素
| 元素 | 说明 | 备注 |
|---|---|---|
| id | 和Mapper命名空间的组合是唯一的 | 命名空间和id组合不唯一,则抛异常 |
| parameterType | 类的全路径或者别名 | 基本数据类型,JavaBean,Map等 |
| resultType | 基本数据类型或者类的全路径,可使用别名(需符合别名规范) | 允许自动匹配的请况下,结果集将通过JavaBean的规范映射,不能和resultMap同时使用 |
| resultMap | 自定义映射规则 | Mybatis最复杂的元素,可以配置映射规则、级联、typeHandler等 |
自动映射
autoMappingBehavior不为NONE时,Mybatis会提供自动映射的功能,只要返回的列名和JavaBean的属性一致,Mybatis就会帮助我们回填这些字段。实际上大部分数据库规范使用下划线分割单词,而Java则是用驼峰命名法,于是需要使用列的别名使得Mybatis能够自动映射,或者在配置文件中开启驼峰命名方式。
1 | <!--SQL列的别名与pojo的属性一样,则SQL查询的结果会自动映射到pojo--> |
自动映射可以在setting元素中配置autoMappingBehavior属性值设定其策略。包含三个值:
- NONE,取消自动映射
- PARTIAL,只会自动映射,没有定义嵌套结果集映射的结果集
- FULL,会自动映射任意复杂的结果集(无论是否嵌套)
默认值是PARTIAL,默认情况下可以做到当前对象的映射,使用FULL是嵌套映射,性能会下降。
如果数据库是规范命名的,即每个单词用下划线分隔,而POJO是驼峰式命名的方式,此时可设置mapUnderscoreToCamelCase为true,这样就可以实现从数据库到POJO的自动映射了。
传递多个参数
- 使用注解方式传递参数
1 | public List<Role> findRoleByCondition( String roleName, String note); |
RoleMapper.xml
1 | <select id="findRoleByCondition" resultMap="roleMap"> |
- 使用JavaBean传递参数
将参数组织成JavaBean,通过getter和setter方法设置参数。
1 | public class RoleParam { |
接口RoleMapper
1 | public List<Role> findRoleByParams2(RoleParam roleParam); |
RoleMapper.xml
1 | <select id="findRoleByParams2" parameterType="com.tyson.pojo.RoleParam" resultMap="roleMap"> |
参数个数多于5,建议使用JavaBean方式。
使用resultMap映射结果集
1 | <resultMap id="roleMap" type="role"> |
insert元素
执行插入之后会返回一个整数,表示插入的记录数。parameterType 为 role(mybatis-config.xml 定义的别名)。
1 | <insert id="insertRole" parameterType="role"> |
主键回填
部分内容参考自:insert主键返回 selectKey使用
设计表的时候有两种主键,一种自增主键,一般为int类型,一种为非自增的主键,例如用uuid等。
自增主键
role表指定id字段为自增字段,对应的Role实体类提供getter和setter方法,便可以使用Mybatis的主键回填功能。通过keyProperty指定主键字段,并使用useGeneratedKeys告诉Mybatis这个主键是否使用数据库内置策略生成。
1 | <!--useGeneratedKeys:默认false,使MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键 |
传入的role无需设置id,Mybatis在插入记录时会自动回填主键。
1 |
|
也可以通过selectKey设置主键回填。
1 | <insert id="insertRole" parameterType="role"> |
非自增主键
假设增加如下需求,当表role没有记录时,则插入第一条记录时id设为1,否则取最大的id加2,设置为新的主键,这个时候可以使用selectKey来处理。
1 | <insert id="myInsertRole" parameterType="role"> |
selectKey标签的语句会被先执行,然后把查询到的id放到role对象。
1 |
|
假设主键是VARCHAR类型,以uuid()方式生成主键。
1 |
|
测试类。
1 | import com.tyson.mapper.CustomerMapper; |
update和delete元素
update和delete元素用于更新记录和删除记录。插入和删除记录执行完成会返回一个整数,表示插入或删除几条记录。
1 | <update id="updateRole" parameterType="role"> |
测试类
1 |
|
sql元素
resultMap元素
resultMap元素主要包括以下元素:
1 | <resultMap id="" type=""> |
constructor元素用于配置构造方法。对于没有无参构造方法的POJO,可用constructor元素进行配置。
1 | <constructor> |
级联
Mybatis中级联分为三种:association、collection和discriminator。
- association,代表一对一关系
- collection,代表一对多关系
- discriminator,鉴别器,它可以根据实际选择选用哪个类作为实例,允许根据特定的条件去关联不同的结果集。
association一对一级联
以学生和学生证为例,学生和学生证是一对一的关系,在Student建立一个类型为StudentCart的属性sc,这样便形成了级联。
1 | public class Student { |
1 | public class StudentCard { |
在StudentCartMapper.xml中提供findStudentCardByStudentId方法。
1 |
|
在StudentMapper里使用StudentCardMapper进行级联。
1 |
|
测试association级联。
1 |
|
测试结果:
1 | 22:37:54.931 [main] INFO com.tyson.StudentTest - id: 1, name: tyson, sex: MALE, cardId: 10086 |
collection一对多级联
一个学生有多门课程,这是一对多的级联。建立Lecture的POJO记录课程和StudentLecture表示学生课程表,StudentLecture里有一个类型为Lecture的属性lecture,用来记录学生成绩。
StudentLecture和Lecture类:
1 | public class StudentLecture { |
1 | public class Lecture { |
Student类添加一个List
1 | public class Student { |
StudentMapper.xml使用collection对Student和StudentLecture做一对多的级联。
1 | <resultMap id="studentMap" type="com.tyson.entity.Student"> |
StudentLectureMapper.xml需要使用association对StudentLecture和Lecture做一对一的级联。
1 |
|
LectureMapper.xml
1 |
|
测试类
1 |
|
测试结果如下:
1 | 10:46:33.916 [main] INFO com.tyson.StudentTest - id: 1, name: tyson, sex: MALE, cardId: 10086, studentLectureList: StudentLecture{studentId=1, lecture=id: 1, lectureName: math, grade=90}, StudentLecture{studentId=1, lecture=id: 2, lectureName: physics, grade=78}, |
discriminator鉴别器级联
鉴别器级联是在特定的条件下去使用不用的POJO。比如可以通过学生信息表的sex属性进行判断关联男生健康指标或者女生的健康指标。新建MaleStudentHealth.java和FemaleStudentHealth.java,存储男生女生的健康信息。新建MaleStudent.java和FemaleStudent.java,继承自Student.java类。
1 | public class MaleStudentHealth { |
StudentMapper.xml如下,在discriminator元素通过sex字段的值判断是男生还是女生。当sex=1时,引入maleStudentMap的resultMap,这个resultMap继承自studentMap,使用collection对MaleStudent和MaleStudentHealth做一对多的级联。
1 |
|
测试结果如下:
1 | 16:39:14.123 [main] INFO com.tyson.StudentTest - MaleStudent{maleStudentHealthList=MaleStudentHealth{height=170}, MaleStudentHealth{height=172}, id=1, name='tyson', sex=MALE, sc=studentCard: 10086, studentLectureList=[StudentLecture{studentId=1, lecture=id: 1, lectureName: math, grade=90}, StudentLecture{studentId=1, lecture=id: 2, lectureName: physics, grade=78}]} |
延迟加载
级联的优势在于能够方便快捷地获取数据,但是每次获取数据时,所有级联数据都会取出,每一个关联都会多执行一次SQL,这样会造成SQL执行过多性能下降。
假如我们通过传入id查找学生信息,然后打印出学生证信息,代码如下:
1 |
|
测试结果如下,所有级联数据都会被加载出来。

为了解决这个问题可以采用延迟加载的功能。首先打开延迟加载的开关。
1 | <settings> |
重新运行测试代码,结果如下:

由图可知,当我们查找学生信息时,会同时查出健康信息,当访问学生课程时,会同时把学生证信息查出。原因是Mybatis默认是按层级延迟加载的,如下图所示:
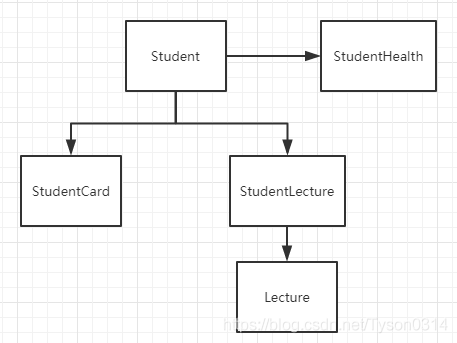
当加载学生信息时,会根据鉴别器找到健康的信息。而当我们访问学生课程时,由于学生证和学生课程是一个层级,也会访问到学生证信息。通过设置全局参数aggressiveLazyLoading可以避免这种情况。aggressiveLazyLoading默认值是true,使用层级加载的策略,设置为false则会按照我们的需要去延迟加载数据。
1 | <settings> |
测试结果如下,此时会根据我们的需要加载数据,不需要的数据不会被加载。

aggressiveLazyLoading是全局的设置,不能指定哪个属性可以立即加载,哪个属性可以延迟加载。假如我们在查找学生信息时,很多情况下需要同时把学生课程成绩查出,此时采用即时加载比较好,多条SQL同时发出,性能高。我们可以在association和collection元素加入属性值fetchType(取值为lazy和eager),便可以实现局部延迟加载的功能。(需先设置aggressiveLazyLoading为false)
StudentMapper.xml设置学生证和健康信息延时加载,学生课程即时加载。
1 | <association property="sc" column="id" fetchType="lazy" select="com.tyson.mapper.StudentCardMapper.findStudentCardByStudentId"/> |
StudentLectureMapper.xml设置课程信息即时加载。
1 | <resultMap id="studentLectureMap" type="com.tyson.entity.StudentLecture"> |
测试代码:
1 | public void findStudentTest() { |
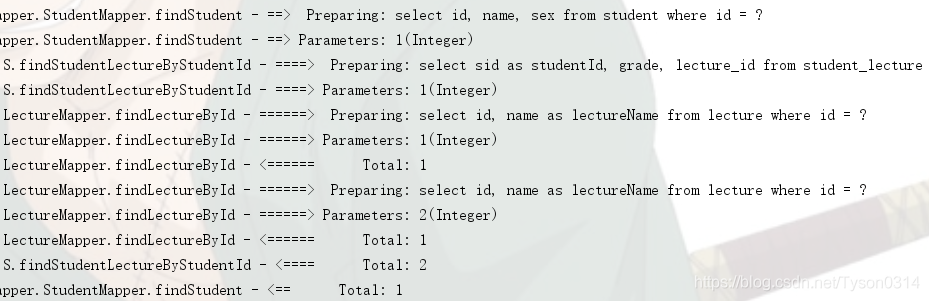
测试结果如下,可以看到有三条SQL被执行,查询学生信息,学生课程和课程信息。当我们访问延迟加载对象时,它才会发送SQL到数据库把数据加载回来。
动态SQL
Mybatis的动态SQL主要包括以下几种元素。
| 元素 | 作用 |
|---|---|
| if | 单条件分支判断 |
| choose(when、otherwise) | 相当于Java的switch、case |
| foreach | 在in语句等列举条件常用 |
| trim(where、set) | 用于处理SQL拼装问题 |
if元素
if元素和test属性联合使用。
1 | <select id="getRoleByRoleName" parameterType="string" resultMap="roleMap"> |
choose元素
choose、when和otherwise类似于Java的switch、case和default。
1 | <select id="findRoles" parameterType="role" resultMap="roleMap"> |
- 当roleName不为空,则只用roleName作为条件查询;
- 当roleName为空,note不为空,则用note作为条件进行查询;
- 当roleName和note都为空时,则以 id != 1 作为查询条件
where元素
where元素解析时会自动将第一个字段的and去掉。
1 | <select id="findRoles" parameterType="role" resultMap="roleMap"> |
测试结果:
1 | 11:42:16.301 [main] DEBUG c.tyson.mapper.RoleMapper.findRoles - ==> Preparing: select id, role_name, note, reg_time from role where note like concat('%', ?, '%') |
使用trim也可以达到同样的效果。prefix代表语句前缀,prefixOverrides代表需要去掉的字符串。
1 | <select id="findRoles" parameterType="role" resultMap="roleMap"> |
set元素
当在 update 语句中使用if标签时,如果前面的if没有执行,则或导致逗号多余错误。使用set标签可以将动态的配置 SET 关键字,并剔除追加到条件末尾的任何不相关的逗号。使用 if+set 标签修改后,如果某项为 null 则不进行更新,而是保持数据库原值。
1 | <update id="updateRole" parameterType="role"> |
测试结果如下,最后一个逗号被去掉了。
1 | 11:39:37.975 [main] DEBUG c.tyson.mapper.RoleMapper.updateRole - ==> Preparing: update role SET role_name = ?, note = ? where id = ? |
foreach元素
foreach用于遍历元素,支持数组、List和Set接口的集合。
1 | <insert id="batchInsertRole" parameterType="java.util.List"> |
RoleMapper.java
1 | //List没有使用@Param指定参数名称,则对应Mapper.xml中的collection名称为list |
| 参数 | 说明 |
|---|---|
| collection | 数组、List或Set接口 |
| item | 当前元素 |
| index | 当前元素在集合的下标 |
| open/close | 用什么符号将集合元素包装起来 |
| separator | 间隔符 |
bind元素
当进行模糊查询时,对于MySQL数据库,我们经常会用concat函数用%和参数连接。对于Oracle则是用||符号连接。这样不同的数据库便需要不同的实现。有了bind元素,就不用考虑使用何种数据库语言,只要使用Mybatis的语言即可与所需参数相连,提高其移植性。
1 | <select id="findRoles" parameterType="role" resultMap="roleMap"> |
测试结果:
1 | 15:05:21.798 [main] DEBUG c.tyson.mapper.RoleMapper.findRoles - ==> Preparing: select id, role_name, note, reg_time from role where role_name like ? and note like ? |
Mybatis-Spring应用
整合Mybatis-Spring可以通过xml的方式配置,也可以通过注解配置。配置Mybatis-Spring分为几个部分:配置数据源、配置SqlSessionFactory、配置SqlSessionTemplate、配置Mapper和事务处理。SqlSessionTemplate是对SqlSession操作的封装。
pom.xml导入依赖。
1 |
|
applicationContext.xml
1 |
|
sqlMapConfig.xml
1 |
|
实体类Role.java
1 | import java.util.Date; |
RoleMapper.java
1 | import com.tyson.pojo.Role; |
RoleMapper.xml
1 |
|
RoleService.java
1 | import com.tyson.pojo.Role; |
RoleServiceImpl.java
1 | import com.tyson.mapper.RoleMapper; |
测试
1 | import com.tyson.pojo.Role; |
实用场景
批量更新
Mybatis内置的ExecutorType有3种,默认的是simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句,并且批量执行所有更新语句。
在数据库中使用批量更新有利于提高性能。在Mybatis中通过修改mybatis-config.xml配置文件中的settings的defaultExecutorType来制定其执行器为批量执行器。
1 | <settings> |
也可以通过Java代码实现批量执行器的使用。
1 | sqlSessionFactory.openSession(ExecutorType.BATCH); |
在Spring中使用批量执行器。
1 | <bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate"> |
使用批量执行器,在默认情况下,它在sqlSession进行commit操作之后才会执行SQL语句。
测试代码如下:
1 |
|
测试结果:
未开启批量执行:
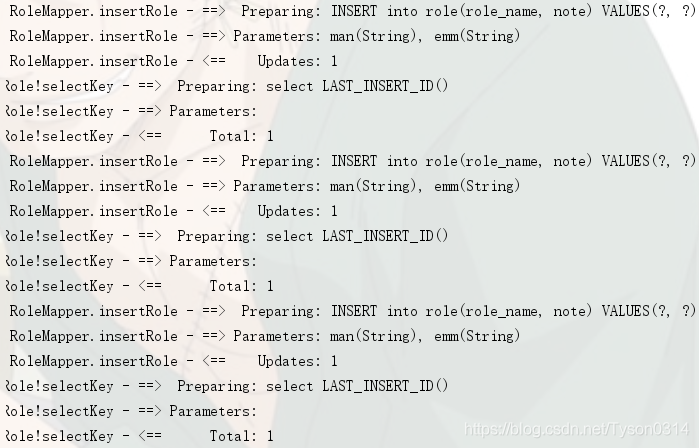
开启批量执行:
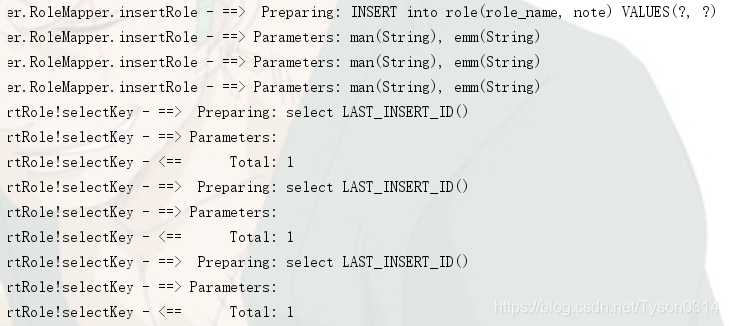
设置ExecutorType.BATCH原理:把SQL语句发给数据库,数据库预编译好,数据库等待需要运行的参数,接收到参数后一次运行,ExecutorType.BATCH只打印一次SQL语句,多次设置参数。
存储过程
存储过程就是具有名字的一段代码,用来完成一个特定的功能。创建的存储过程保存在数据库的数据字典中。
优点(为什么要用存储过程?):
①将重复性很高的一些操作,封装到一个存储过程中,简化了对这些SQL的调用
②批量处理:SQL+循环,减少流量
in和out参数
1.新建存储过程,按照传入的参数查询男女学生人数。
1 | #声明分隔符,默认为“;",编译器将两个$之间的内容当做存储过程的代码,不会执行这些代码 |
调用存储过程。
1 | SET @ges_count=1; |
2.定义一个Pojo反映存储过程的参数。
1 | public class ProcedureParam { |
3.在xml映射器做配置,调用存储过程。
1 | <!--statementType="CALLABLE"表示用存储过程执行它,通过配置mode,mybatis会帮我们回填gesCount--> |
4.存储过程接口。
1 | public void gesCount(ProcedureParam procedureParam); |
5.测试代码。
1 |
|
游标
游标可以遍历返回的多行结果。Mysql中游标只适合存储过程和函数。
语法:
1.定义游标:declare cur_name cursor for select 语句;
2.打开游标:open cur_name;
3.获取结果:fetch cur_name into param1, param2, …;
4.关闭游标:close cur_name;
1 | DROP PROCEDURE IF EXISTS find_customer; |
调用存储过程。
1 | TRUNCATE TABLE customer_tmp; |
分页
RowBounds分页
RowBounds分页是Mybatis内置的基本功能,在任何的select语句中都可以使用,它是在SQL语句查询出所有结果之后,对结果进行截断,当SQL语句返回大量结果时,容易造成内存溢出。其适用于返回数据量小的查询。
RowBounds有两个重要的参数limit和offeset,offeset表示从哪一条记录开始读取,limit表示限制返回的记录数。
下面通过角色名称模糊查询角色信息。
1 | <!--使用resultMap进行结果映射, 用typeHandler对note字段进行转化--> |
RoleMapper接口定义。
1 | import com.tyson.pojo.Role; |
测试代码。
1 |
|
测试结果返回五条记录。
预编译
#{ } 被解析成预编译语句,预编译之后可以直接执行,不需要重新编译sql。
1 | //sqlMap 中如下的 sql 语句 |
${ } 仅仅为一个字符串替换,每次执行sql之前需要进行编译,存在 sql 注入问题。
1 | select * from user where name = '${name}' |
数据库接受到sql语句之后,需要词法和语义解析,优化sql语句,制定执行计划。这需要花费一些时间。如果一条sql语句需要反复执行,每次都进行语法检查和优化,会浪费很多时间。预编译语句就是将sql语句中的值用占位符替代,即将sql语句模板化。一次编译、多次运行,省去了解析优化等过程。
mybatis是通过PreparedStatement和占位符来实现预编译的。
mybatis底层使用PreparedStatement,默认情况下,将对所有的 sql 进行预编译,将#{}替换为?,然后将带有占位符?的sql模板发送至mysql服务器,由服务器对此无参数的sql进行编译后,将编译结果缓存,然后直接执行带有真实参数的sql。
预编译的作用:
预编译阶段可以优化 sql 的执行。预编译之后的 sql 多数情况下可以直接执行,数据库服务器不需要再次编译,可以提升性能。
预编译语句对象可以重复利用。把一个 sql 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个sql,可以直接使用这个缓存的 PreparedState 对象。
防止SQL注入。使用预编译,而其后注入的参数将
不会再进行SQL编译。也就是说其后注入进来的参数系统将不会认为它会是一条SQL语句,而默认其是一个参数。
缓存
目前流行的缓存服务器有Redis、Ehcache、MangoDB等。缓存是计算机内存保存的数据,在读取数据的时候不用从磁盘读入,具备快速读取的特点,如果缓存命中率高,可以极大提升系统的性能。若缓存命中率低,则使用缓存意义不大,故使用缓存的关键在于存储内容访问的命中率。
一级缓存和二级缓存
Mybatis对缓存提供支持,默认情况下只开启一级缓存,一级缓存作用范围为同一个SqlSession。在SQL和参数相同的情况下,我们使用同一个SqlSession对象调用同一个Mapper方法,往往只会执行一次SQL。因为在使用SqlSession第一次查询后,Mybatis会将结果放到缓存中,以后再次查询时,如果没有声明需要刷新,并且缓存没超时的情况下,SqlSession只会取出当前缓存的数据,不会再次发送SQL到数据库。若使用不同的SqlSession,因为不同的SqlSession是相互隔离的,不会使用一级缓存。
二级缓存作用范围是Mapper(Namespace),可以使缓存在各个SqlSession之间共享。二级缓存默认不开启,需要在mybatis-config.xml开启二级缓存:
1 | <!-- 通知 MyBatis 框架开启二级缓存 --> |
并在相应的Mapper.xml文件添加cache标签,表示对哪个mapper 开启缓存:
1 | <cache/> |
二级缓存要求返回的POJO必须是可序列化的,即要求实现Serializable接口。
当开启二级缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
原理
当调用Mapper接口方法的时候,Mybatis会使用JDK动态代理返回一个Mapper代理对象,代理对象会拦截接口方法,根据接口的全路径和方法名,定位到sql,使用executor执行sql语句,然后将sql执行结果返回。
因为mybatis动态代理寻找策略是 全限定名+方法名,不涉及参数,所以不支持重载。
优缺点
优点:
- SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。
- 开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。
- 与各种数据库兼容。
缺点:
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。

