一级缓存
1.在一个sqlSession中,对User表根据id进行两次查询,查看他们发出sql语句的情况
1 |
|
查看控制台打印情况: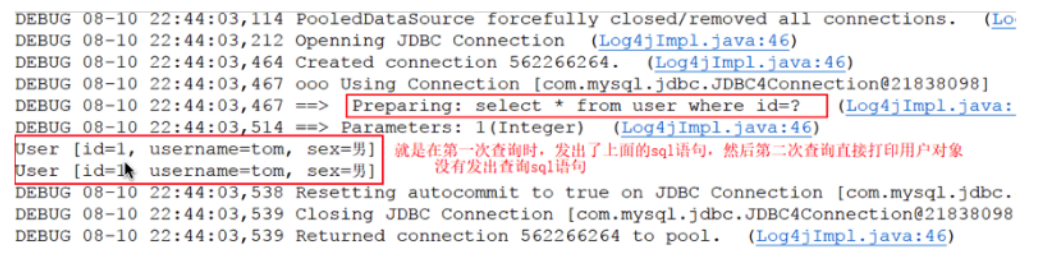
2.同样是对user表进行两次查询,只不过两次查询之间进行了一次update操作。
1 |
|
查看控制台打印情况: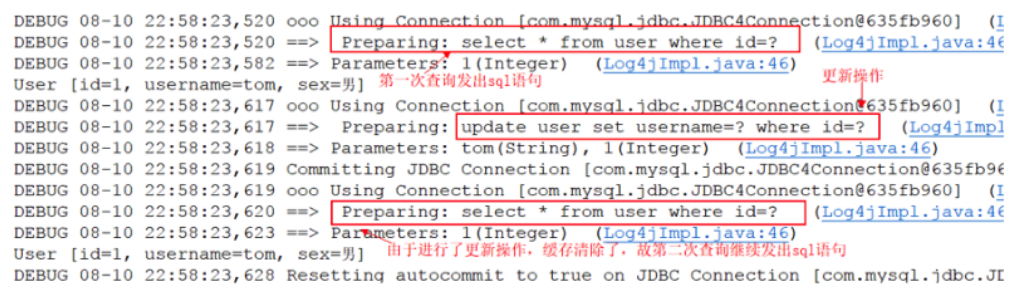
3.总结
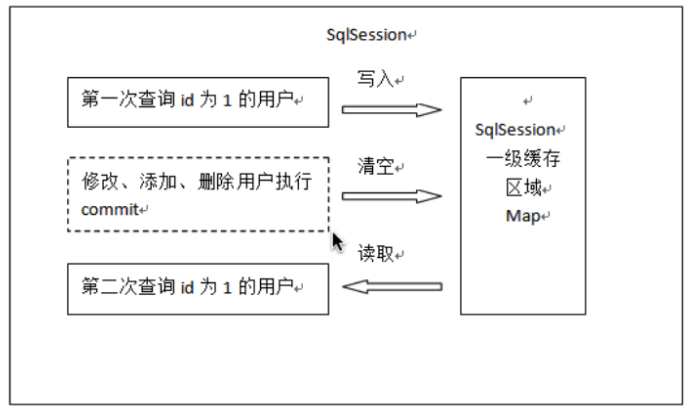
- 第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
- 如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
- 第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
一级缓存原理探究与源码分析
一级缓存到底是什么?一级缓存什么时候被创建、一级缓存的工作流程是怎样的?相信你现在应该会有这几个疑问,那么我们本节就来研究一下一级缓存的本质
大家可以这样想,上面我们一直提到一级缓存,那么提到一级缓存就绕不开SqlSession,所以索性我们就直接从SqlSession,看看有没有创建缓存或者与缓存有关的属性或者方法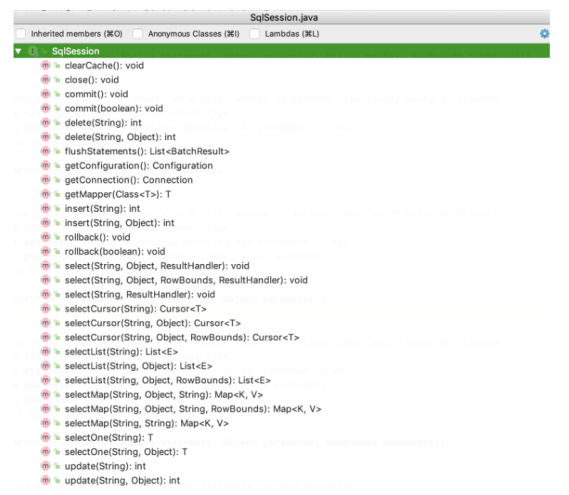
调研了一圈,发现上述所有方法中,好像只有clearCache()和缓存沾点关系,那么就直接从这个方法入手吧,分析源码时,我们要看它(此类)是谁,它的父类和子类分别又是谁,对如上关系了解了,你才会对这个类有更深的认识,分析了一圈,你可能会得到如下这个流程图
再深入分析,流程走到Perpetualcache中的clear()方法之后,会调用其cache.clear()方法,那么这个cache是什么东西呢?点进去发现,cache其实就是private Map cache = new HashMap();也就是一个Map,所以说cache.clear()其实就是map.clear(),也就是说,缓存其实就是本地存放的一个map对象,每一个SqISession都会存放一个map对象的引用,那么这个cache是何时创建的呢?
你觉得最有可能创建缓存的地方是哪里呢?我觉得是Executor,为什么这么认为?因为Executor是执行器,用来执行SQL请求,而且清除缓存的方法也在Executor中执行,所以很可能缓存的创建也很有可能在Executor中,看了一圈发现Executor中有一个createCacheKey方法,这个方法很像是创建缓存的方法啊,跟进去看看,你发现createCacheKey方法是由BaseExecutor执行的,代码如下
1 | CacheKey cacheKey = new CacheKey(); |
创建缓存key会经过一系列的update方法,udate方法由一个CacheKey这个对象来执行的,这个update方法最终由updateList的list来把五个值存进去,对照上面的代码和下面的图示,你应该能理解这五个值都是什么了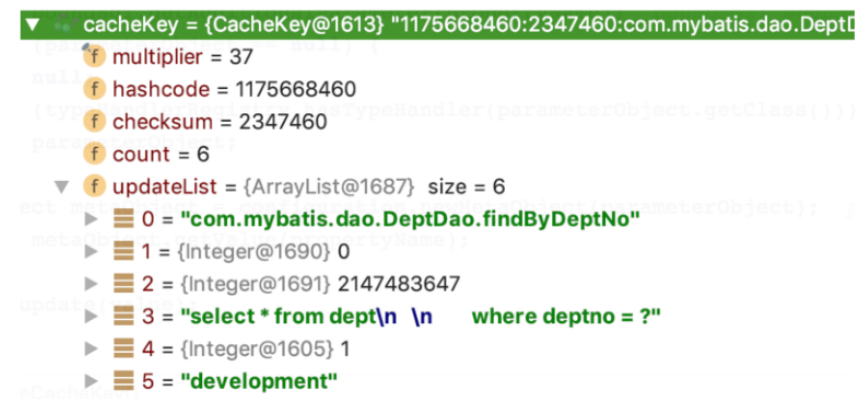
这里需要注意一下最后一个值,configuration.getEnvironment().getId()这是什么,这其实就是定义在mybatis-config.xml中的标签,见如下。
1 | <environments default="development"> |
那么我们回归正题,那么创建完缓存之后该用在何处呢?总不会凭空创建一个缓存不使用吧?绝对不会的,经过我们对一级缓存的探究之后,我们发现一级缓存更多是用于查询操作,毕竟一级缓存也叫做查询缓存吧,为什么叫查询缓存我们一会儿说。我们先来看一下这个缓存到底用在哪了,我们跟踪到query方法如下:
1 | Override |
如果查不到的话,就从数据库查,在queryFromDatabase中,会对localcache进行写入。localcache对象的put方法最终交给Map进行存放
1 | private Map<Object, Object> cache = new HashMap<Object, Object>(); |
二级缓存
二级缓存的原理和一级缓存原理一样,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于sqlSession的,而二级缓存是基于mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中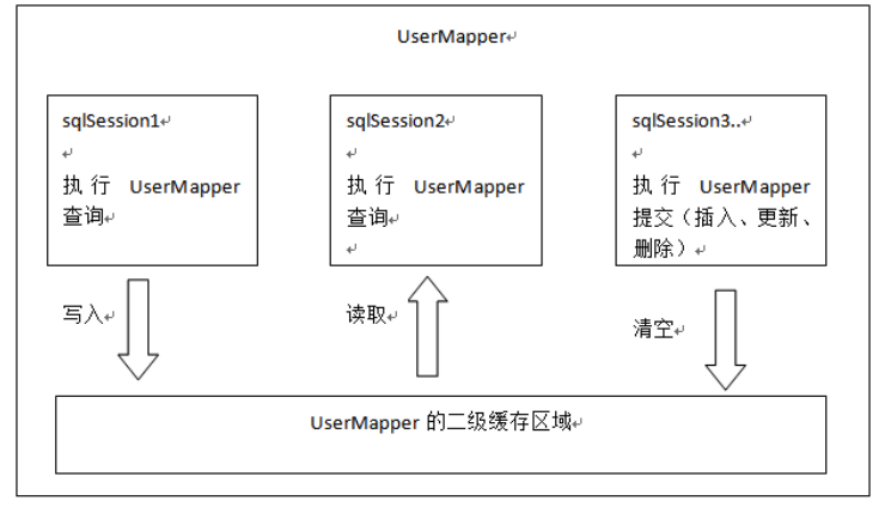
如何使用二级缓存
开启二级缓存
和一级缓存默认开启不一样,二级缓存需要我们手动开启
首先在全局配置文件sqlMapConfig.xml文件中加入如下代码:
1 | <!--开启二级缓存--> |
其次在UserMapper.xml文件中开启缓存
1 | <!--开启二级缓存--> |
我们可以看到mapper.xml文件中就这么一个空标签,其实这里可以配置,PerpetualCache这个类是mybatis默认实现缓存功能的类。我们不写type就使用mybatis默认的缓存,也可以去实现Cache接口来自定义缓存。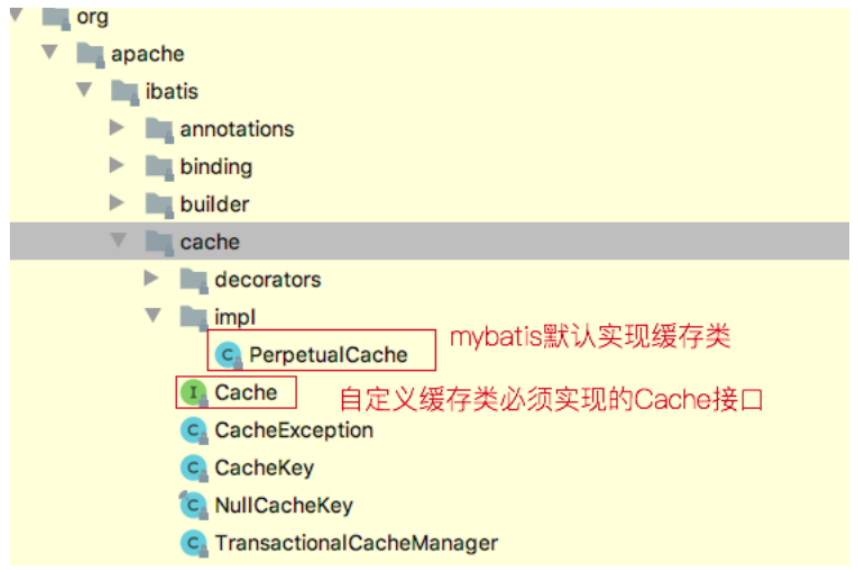
1 | public class PerpetualCache implements Cache { |
我们可以看到二级缓存底层还是HashMap结构
1 | public class User implements Serializable( |
开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口
测试
测试二级缓存和sqlSession无关
1 |
|
可以看出上面两个不同的sqlSession,第一个关闭了,第二次查询依然不发出sql查询语句
测试执行commit()操作,二级缓存数据清空
1 |
|
查看控制台情况: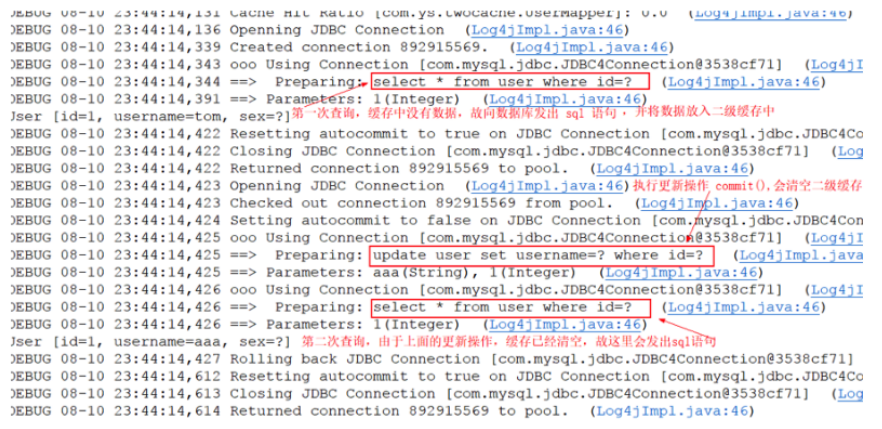
useCache和flushCache
mybatis中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存
1 | <select id="selectUserByUserId" useCache="false" resultType="com.lagou.pojo.User" parameterType="int"> |
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存,直接从数据库中获取。
在mapper的同一个namespace中,如果有其它insert、update, delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true”属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
1 | <select id="selectUserByUserId" flushCache="true" useCache="false" resultType="com.lagou.pojo.User" parameterType="int"> |
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不用设置,默认即可
二级缓存整合redis
上面我们介绍了mybatis自带的二级缓存,但是这个缓存是单服务器工作,无法实现分布式缓存。那么什么是分布式缓存呢?假设现在有两个服务器1和2,用户访问的时候访问了1服务器,查询后的缓存就会放在1服务器上,假设现在有个用户访问的是2服务器,那么他在2服务器上就无法获取刚刚那个缓存,如下图所示: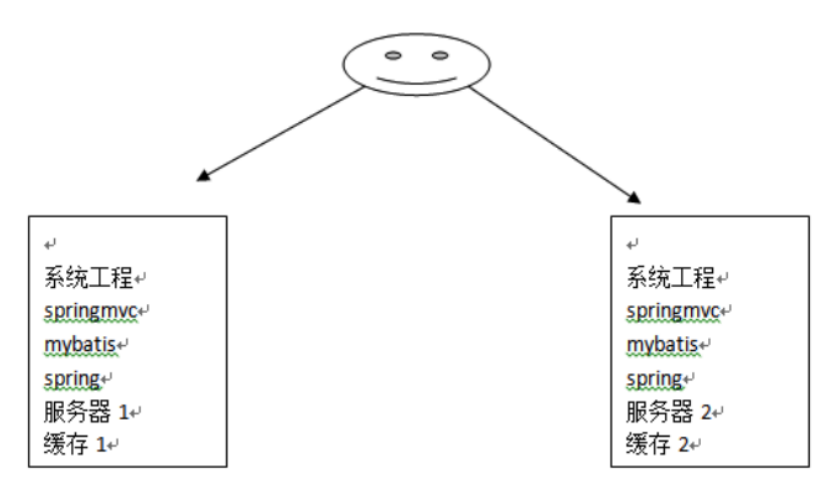
为了解决这个问题,就得找一个分布式的缓存,专门用来存储缓存数据的,这样不同的服务器要缓存数据都往它那里存,取缓存数据也从它那里取,如下图所示: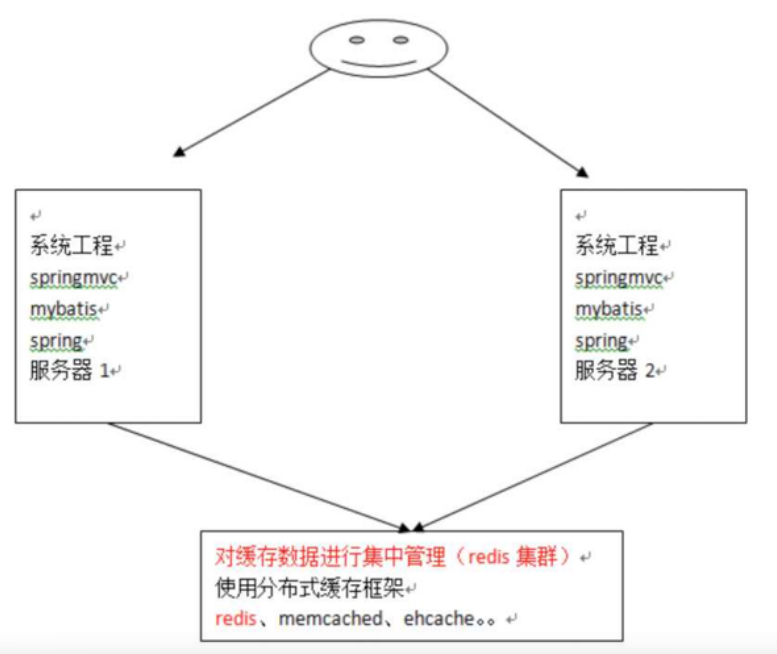
如上图所示,在几个不同的服务器之间,我们使用第三方缓存框架,将缓存都放在这个第三方框架中, 然后无论有多少台服务器,我们都能从缓存中获取数据。
这里我们介绍mybatis与redis的整合。
刚刚提到过,mybatis提供了一个eache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。mybatis本身默认实现了一个,但是这个缓存的实现无法实现分布式缓存,所以我们要自己来实现。redis分布式缓存就可以,mybatis提供了一个针对cache接口的redis实现类,该类存在mybatis-redis包中
实现:
pom文件
1 | <dependency> |
配置文件
Mapper.xml
1 |
|
redis.properties
1 | redis.host=localhost |
测试
1 |
|
源码分析:
RedisCache和大家普遍实现Mybatis的缓存方案大同小异,无非是实现Cache接口,并使用jedis操作缓存;不过该项目在设计细节上有一些区别;
1 | public final class RedisCache implements Cache { |
RedisCache在mybatis启动的时候,由MyBatis的CacheBuilder创建,创建的方式很简单,就是调用RedisCache的带有String参数的构造方法,即RedisCache(String id);而在RedisCache的构造方法中,调用了 RedisConfigu rationBuilder 来创建 RedisConfig 对象,并使用 RedisConfig 来创建JedisPool。
RedisConfig类继承了 JedisPoolConfig,并提供了 host,port等属性的包装,简单看一下RedisConfig的属性:
1 | public class RedisConfig extends JedisPoolConfig { |
RedisConfig对象是由RedisConfigurationBuilder创建的,简单看下这个类的主要方法:
1 | public RedisConfig parseConfiguration(ClassLoader classLoader) { |
核心的方法就是parseConfiguration方法,该方法从classpath中读取一个redis.properties文件:
1 | host=localhost |
并将该配置文件中的内容设置到RedisConfig对象中,并返回;接下来,就是RedisCache使用RedisConfig类创建完成edisPool;在RedisCache中实现了一个简单的模板方法,用来操作Redis:
1 | private Object execute(RedisCallback callback) { |
模板接口为RedisCallback,这个接口中就只需要实现了一个doWithRedis方法而已:
1 | public interface RedisCallback { |
接下来看看Cache中最重要的两个方法:putObject和getObject,通过这两个方法来查看mybatis-redis储存数据的格式:
1 |
|
可以很清楚的看到,mybatis-redis在存储数据的时候,是使用的hash结构,把cache的id作为这个hash的key(cache的id在mybatis中就是mapper的namespace);这个mapper中的查询缓存数据作为hash的field,需要缓存的内容直接使用SerializeUtil存储,erializeUtil和其他的序列化类差不多,负责对象的序列化和反序列化;
阅读量
